728x90
결정 트리 (Decision Tree)
- 예/아니오에 대한 질문을 이어나가면서 정답을 찾아 학습하는 알고리즘
- 비교적 예측 과정을 이해하기 쉽고 성능도 뛰어남
- 사이킷런의 DecisionTreeClassifier 클래스
- max_depth 매개변수 : 트리의 최대 깊이 지정
- 특성값의 스케일은 결정 트리 알고리즘에 영향 X
- 표준화 전처리 과정이 필요 X
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target)) # 0.997
print(dt.score(test_scaled, test_target)) # 0.859
# 과대적합- 모델을 그림으로 표현 가능
- 사이킷런의 plot_tree() 함수
- 맨 위의 노드 : 루트 노드
- 맨 아래 끝에 달린 노드 : 리프 노드
- 리프 노드에서 가장 많은 클래스가 예측 클래스
- 트리 깊이 제한도 가능
- max_depth 매개변수
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# 전체
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
# 트리 깊이 제한
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()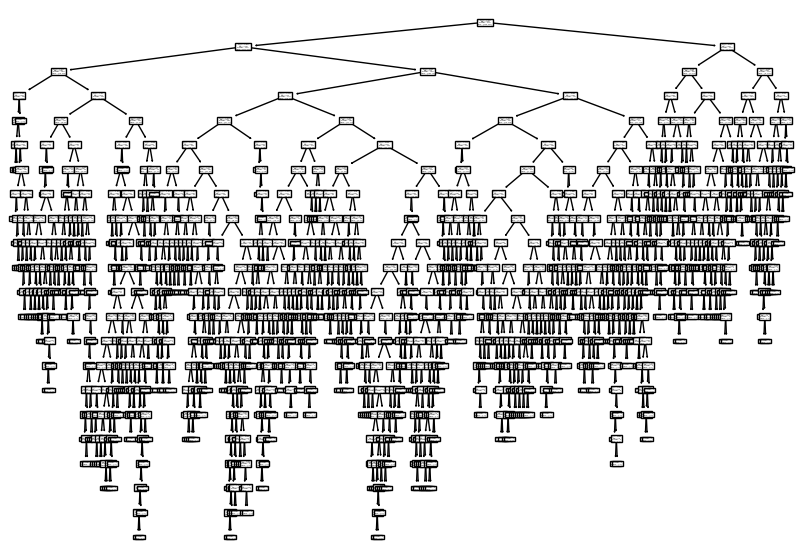
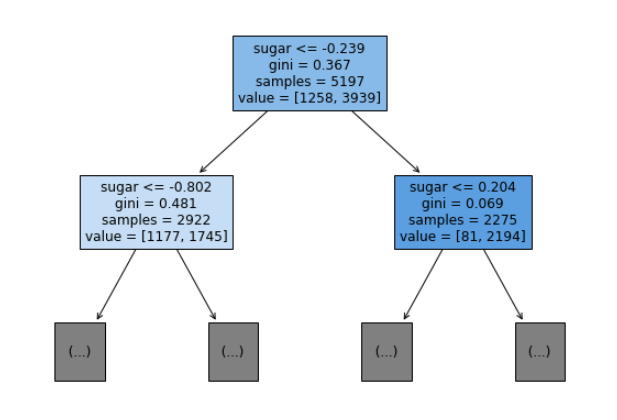
불순도
- 결정 트리가 최적의 질문을 찾기 위한 기준
- 여러 가지 클래스가 섞여 있는 정도
- DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값이 'gini'
- criterion 매개변수 : 노드에서 데이터를 분할할 기준을 정하는 것
- 지니 불순도
- 1 - (음성 클래스 비율^2 + 양성 클래스 비율^2)
- 0 ~ 0.5
- 클래스가 정확히 1/2씩이라면 불순도가 0.5로 최악
- 불순도 0인 노드 : 순수 노드
- 결정 트리 모델은 부모 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장시킴
- 불순도 차이 == 정보 이득
728x90
반응형
'TIL - 외 > 빅데이터' 카테고리의 다른 글
| 코호트 분석1 (0) | 2023.06.19 |
|---|---|
| [머신러닝] 랜덤 포레스트 (Random Forest) (0) | 2023.05.24 |
| 엘로 평점 시스템 (Elo Rating System) (0) | 2023.05.18 |
| [머신러닝] 로지스틱 회귀 (0) | 2023.05.07 |
| [머신러닝] 회귀 알고리즘 및 실습 (0) | 2023.04.13 |

댓글