728x90
로지스틱 회귀
- 선형 방정식을 사용한 분류 알고리즘
- 범주형 변수를 예측
- 선형 회귀처럼 계산한 값을 그대로 출력하는 것이 아니라 0~1 사이로 압축
- 이진 분류 -> 시그모이드 함수
- 다중 분류 -> 소프트맥스 함수
- 기본적으로 릿지 회귀와 같이 계수의 제곱을 규제
- L2 규제
- C : 규제를 제어하는 매개변수
- 작을수록 규제가 크다
- 기본값 1
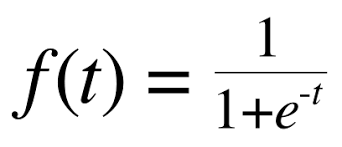
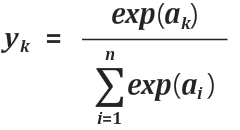
생선 데이터를 통해 어떤 생선인지 분류(7종류)
- 데이터 가져오기
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
# 생선 종류
print(pd.unique(fish['Species']))
# ['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']- input 데이터와 target 데이터로 나누기
# target은 생선 종류인 Species
fish_target = fish['Species'].to_numpy()
# input은 나머지
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()to_numpy() 메서드로 넘파이 배열로 바꾸기
- train 데이터와 test 데이터로 나누기 + 표준화
from sklearn.model_selection import train_test_split
# train과 test로 나누기 (0.75:0.25)
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)
# 표준화 전처리
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)이진 분류 (Bream 과 Smelt)
- 데이터 선택
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]- 로지스틱 회귀
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)
# 결과 예측
print(lr.predict(train_bream_smelt[:5]))
# ['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
# 결과 확률 예측
print(lr.predict_proba(train_bream_smelt[:5]))
'''
[[0.99759855 0.00240145]
[0.02735183 0.97264817]
[0.99486072 0.00513928]
[0.98584202 0.01415798]
[0.99767269 0.00232731]]
'''
# 선형 방정식 만들기
print(lr.coef_, lr.intercept_)
# [[-0.4037798 -0.57620209 -0.66280298 -1.01290277 -0.73168947]] [-2.16155132]선형 방정식
z = -0.40 x (Weight) -0.58 x (Length) -0.66 x (Diagonal) -1.01 x (Height) -0.73 x (Width) -2.16
- z값 예측 + 확률 구하기
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions)
# [-6.02927744 3.57123907 -5.26568906 -4.24321775 -6.0607117 ]
# 확률 구하기 -> 시그모이드
from scipy.special import expit
print(expit(decisions))
# [0.00240145 0.97264817 0.00513928 0.01415798 0.00232731]양성 클래스의 z 값을 반환, 예측
다중 분류
- 로지스틱 회귀
lr = LogisticRegression(C=20, max_iter=1000)
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target)) # 0.93
print(lr.score(test_scaled, test_target)) #0.92max_iter 매개변수에서 반복 횟수를 지정, 기본값 100
위 데이터셋을 사용해 모델을 훈련하면 반복 횟수가 부족하다는 경고가 발생해 반복 횟수를 1000으로 늘렸다.
- 예측
# 예측
print(lr.predict(test_scaled[:5]))
# ['Perch' 'Smelt' 'Pike' 'Roach' 'Perch']
# 예측 확률
proba = lr.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=3))
'''
[[0. 0.014 0.841 0. 0.136 0.007 0.003]
[0. 0.003 0.044 0. 0.007 0.946 0. ]
[0. 0. 0.034 0.935 0.015 0.016 0. ]
[0.011 0.034 0.306 0.007 0.567 0. 0.076]
[0. 0. 0.904 0.002 0.089 0.002 0.001]]
'''
# z값 계산 후 예측 확률 (소프트 맥스)
decision = lr.decision_function(test_scaled[:5])
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3))
'''
[[0. 0.014 0.841 0. 0.136 0.007 0.003]
[0. 0.003 0.044 0. 0.007 0.946 0. ]
[0. 0. 0.034 0.935 0.015 0.016 0. ]
[0.011 0.034 0.306 0.007 0.567 0. 0.076]
[0. 0. 0.904 0.002 0.089 0.002 0.001]]
'''728x90
반응형
'TIL - 외 > 빅데이터' 카테고리의 다른 글
| [머신러닝] 트리 알고리즘 (DecisionTreeClassifier) (0) | 2023.05.24 |
|---|---|
| 엘로 평점 시스템 (Elo Rating System) (0) | 2023.05.18 |
| [머신러닝] 회귀 알고리즘 및 실습 (0) | 2023.04.13 |
| [머신러닝] K-최근접 이웃(KNN) 알고리즘 및 실습 (0) | 2023.04.09 |
| 불균형 데이터 (imbalanced data) 처리를 위한 샘플링 기법 (0) | 2023.03.22 |



댓글